 back to home
back to home
Getting started with mCrl2 via State Machines
The heart of most systems can be described as lots of simple state machines. One of the best ways to understand how large systems work is describing them as independent little finite state machines. In this intro article I’ll describe some of the ways of directly creating state machines, as well as some ways to review and run simulations with them.
mCrl2 can be a pretty intimidating toolset. While the official documentation has some great tutorials there focus is often on academic problems and proving solutions to logic problems. I’m hoping to adopt these same techniques to designing, documenting, and building large and small software systems. I not talking about proving consensus protocols (although I’m sure you could) and other algorithms. Instead I want to focus on business process and how it is delivered via service and communication design.
Similar approaches
I’ve been on a journey finding ways to find system design problems with as little effort as possible for a while. I’ve lost count of the different approaches tried over the years, but a short list of tools I’ve found useful
Each approach has unique strengths, and applied in the right circumstance gives insight into problems I never would have without them. One toolset that I haven’t seen discussed much is mCrl2. Given the differing strengths of tools I tend to start with Alloy doing domain modelling of data structures. Next, and this heavily depends on the project, I’ll module some aspect of how the domain changes over time. This might be a state chart, or data flow. But my goal is to gain further insight in how the domain values may change over time. If I really need to understand temporal properties (deadlock, locklock, only deadlocks after some event) building TLA+ model never fails to give further additional knowledge of the design.
However I’ve found most designs are best to start simple and evolve to cover the whole problem space. The above approaches are a bit notorious for not composing up to a larger whole. It’s my belief that mCrl2 provides good enough domain modeling (with a type system that feels very similar oCaml or other MLs), a great process model, and as ways to describe how these values transition in a running system. In this article I’m going to focus on the simplest of transition systems.
A Short Background
Before jumping straight into a tutorial, let’s lay some pretty basic groundwork on mCrl2. mCrl2 is a collection of tools which deal with around a dozen different file formats. Having all of these specialized formats helps focus each file on a single meaning. One trade-off is the confusion this breadth of causes while learning. In this article, I’m only going to describe on the labeled transition system(LTS) formats.
Labeled Transistion Systems(LTL)
An LTL is much like a finite state machine[5](FSM), in fact a FSM is specific type of LTS[6]. Both consist of a set of states and transitions between the states. LTSs additionally always have transitions labeled with an action name. This just means that every line and arrow you see pointing to something will have some accompanying text. The difference between FSMs and LTSs as far as I’m aware is that an FSM is explicitly finite while a LTSs may be infinite. For what we care about now this distinction isn’t important, but it means we can both model, simulate and sample systems with an infinite set of states. Perhaps unsurprisingly modeling information systems or systems which exchange information often have sections which infinite states is at least an interesting property.
mCrl2 offers many tools which can help with designing and understanding FSMs or LTSs. With the tools you can simulated transitions, generate traces, and test if one FSM is "contained" in another.
If you haven’t already now is a good time to go to mcrl2.org and download and install the toolset. Everything you need will be in one package with the latest release download, and it’s supported in most OSs.
Defining a Simple Switch as and FSM

We are going to write a specification, simulation and a visualization of a simple switch. While this is a vast implication to most systems we deal with, the approach is similar to all FSMs. Our specification will only ensure the transition from on to off with a flick action and that it can also transition from off to on also with a flick action.
| Current State | Input | Next State | Output |
|---|---|---|---|
|
Off |
flick |
On |
Turns the light on |
|
On |
flick |
Off |
Turns the light off |
Checking our expectations
Learning a new syntax is a bit challenging. I’ve always found I (and most people I’ve worked with) learn best when they can check their own expectations. For the current FSM file, we can verify the state, transitions and actions using the ltsinfo tool.
$ ltsinfo simple_switch.fsm
> Number of states: 2. (1)
> Number of action labels: 2 (including a tau label). (2)
> Number of transitions: 2. (3)
> Number of state labels: 2. (4)
> LTS is deterministic. (5)
> This lts has no probabilistic states.| 1 | Our 2 states as expected given our two line length state section |
| 2 |
This one is a bit surprising! We only defined a flick but it counts two, and has some confusing tau label statement.
|
| 3 |
Our 2 transitions from Off—flick→On and On—flick→Off
|
| 4 | Labels for our 2 states (this is unfortunately not the "Off" and "On" but the indexes.) |
| 5 | That our LTS is deterministic (every state→action leads to just one other state) |
There are other command switches we can pass to ltsinfo to get the list of actions and list of states as well. But the important thing for now is we can get feedback that our FSM file is valid, and that it contains the info we expect.
Generating a static visualization of an FSM
First lets generate a quick state visualization of FSM. In a terminal run,
$ ltsconvert simple_switch.fsm simple_switch.dot
$ dot -Tsvg simple_switch.dot > simple_switch.svgYou will now have 2 additional files in your directory. One is a dot file[7] one is an svg image. It should be similar to the image shown to the right. It should look pretty familiar as a simplified state diagram.
This quick visualization of a great artifact to review, with everyone technical and non-technical on your project. It might not be pretty but I’ve found that a quick visualization of a state machine helps all parties better understand what’s being built. If the your visualization is too complicated to really make sense at this point we can move on to the next approach of simulations.
Simulation the switch
Using the same FSM file we can "click through" to different states in a cheap and simple simulation.
There are two different tools that can help with this we will use ltsview.
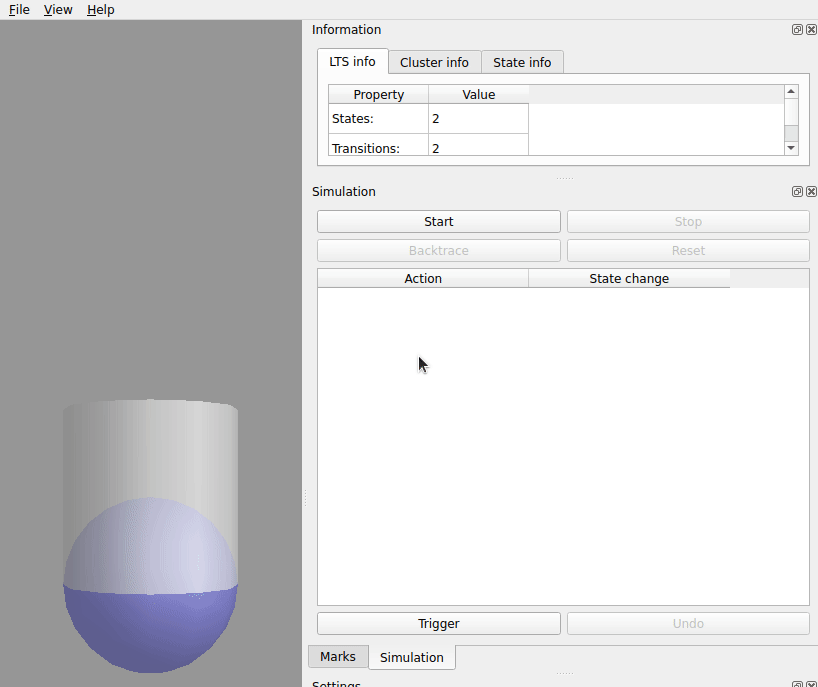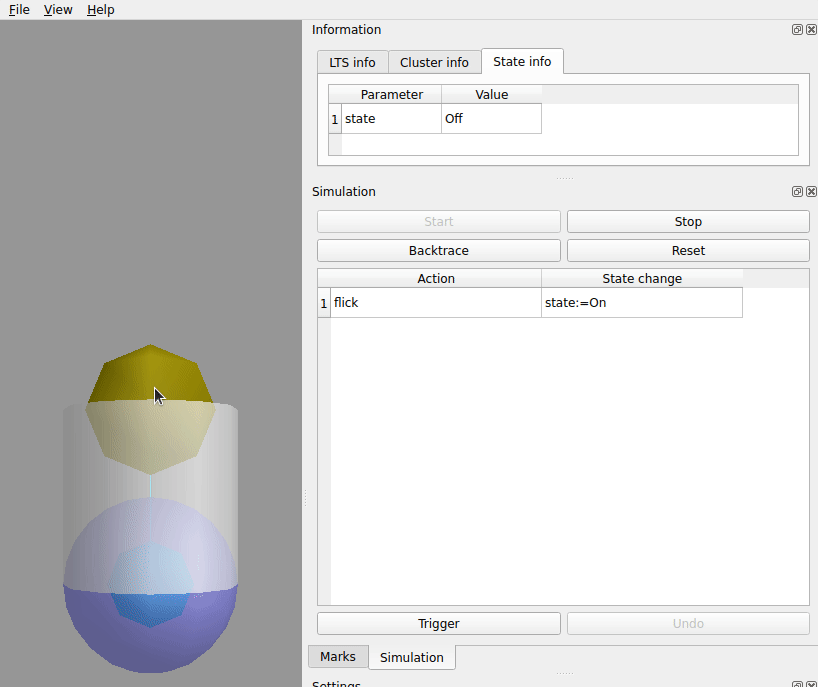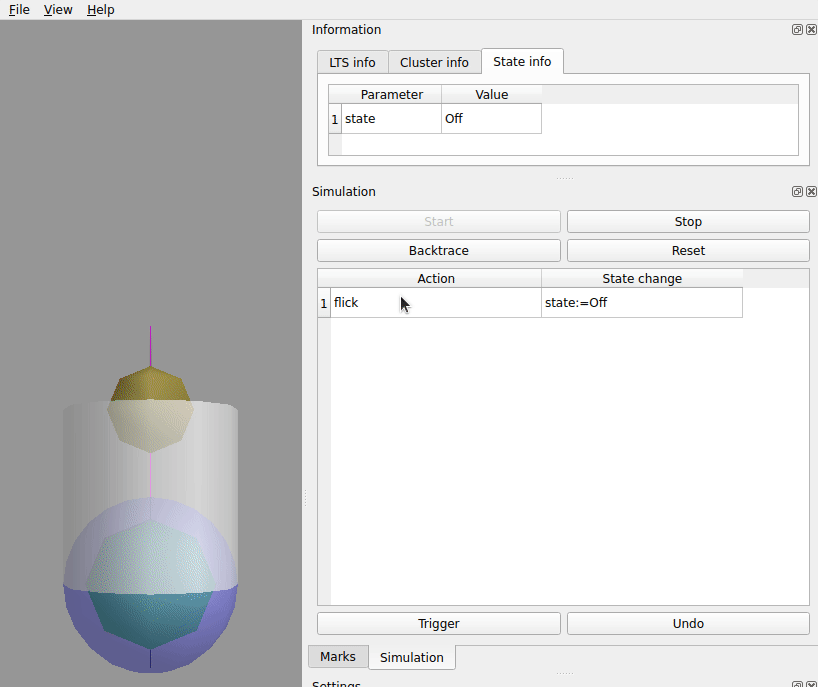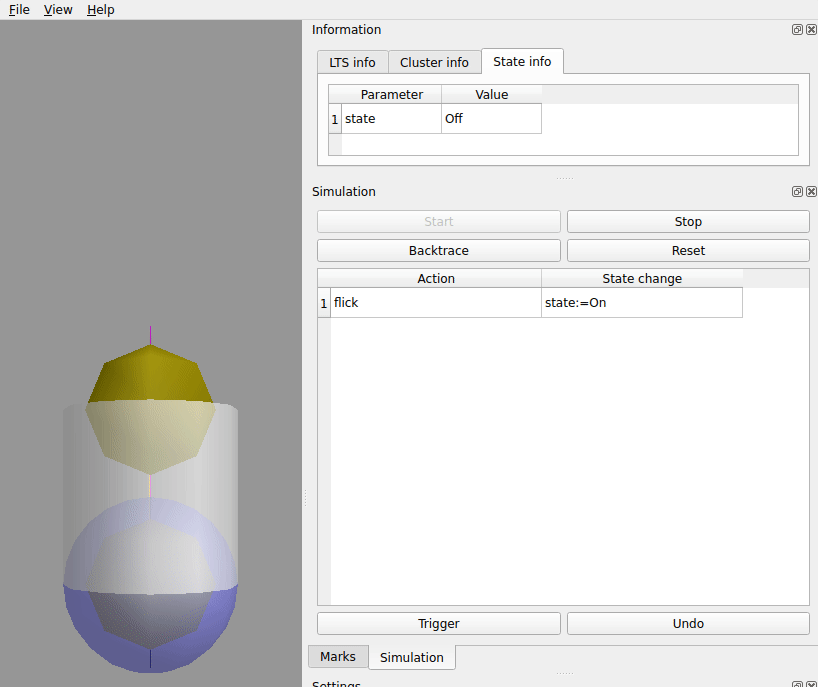
click the Start button.
| Action | State Change | |
|---|---|---|
|
1 |
flick |
state:=On |
Under and in the graph to the left click the top sphere.
double click the flick row.
| Action | State Change | |
|---|---|---|
|
1 |
flick |
state:=Off |
Click for an alternative simulation method
There is a lot of other distractions present on in this UI, which doesn’t help with such a simple case. So often at this point I simulate it a different way. I won’t go into the details in this article, but we can convert the LTS to a process specification and use the process simulation tooling which helps with the simulation focus.
$ lts2lps simple_switch.fsm -Ddata.mcrl2 simple_switch.lps
You can then run a similar simulation with lpssim or lpsxsim.
A couple of things to note after this simulation and visualization, the FSM defines an infinite amount of "flick" actions. It defines what the state would be after any number of flicks. It always starts at in the "Off" state. We will use these concepts in another post to prove a more complicated switch holds these same properties. If we wanted a weaker set of properties of the same switch we could simulate the actions, and save a trace.
This seems was a lot of effort for something as simple as an On / Off switch. But if you have a domain which can be modeled in simple state machines you can share these different approaches (visualization, action listing and simulation) with everyone on your team.